Cluster
The Cluster area monitors and manages the nodes of a high availability cluster. It adapts to the deployment: a clustered server shows the full cluster console, while a standalone server shows an informational page about this single node. The page is a live status surface and refreshes automatically.
Standalone server
On a standalone server the page explains that all configuration and data live on this single node, and that there are no peers to monitor or manage.
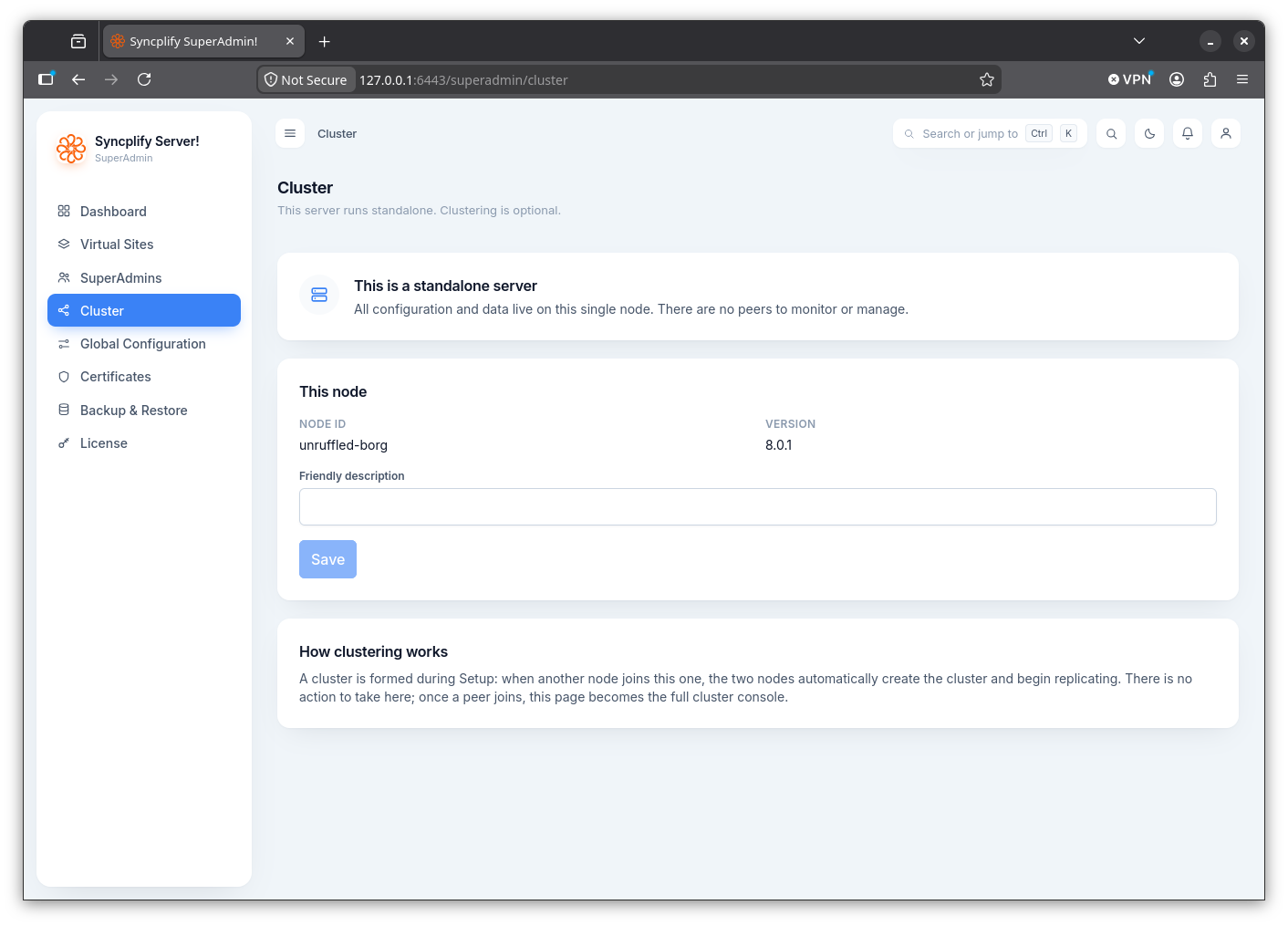
It shows this node's ID and version, and lets you set a friendly description for the node. A short explanation describes how clustering works: a cluster is formed during setup, and when another node joins, the two nodes automatically create the cluster and begin replicating; once a peer joins, this page becomes the full cluster console.
NOTE
High availability clustering may require a higher license edition. When it is not licensed, a notice explains the limit.
Clustered server
In a cluster the page opens with an overview showing this node, the total number of nodes, how many are online, the last replication time, and an overall cluster state (Active, Degraded, or Standalone).
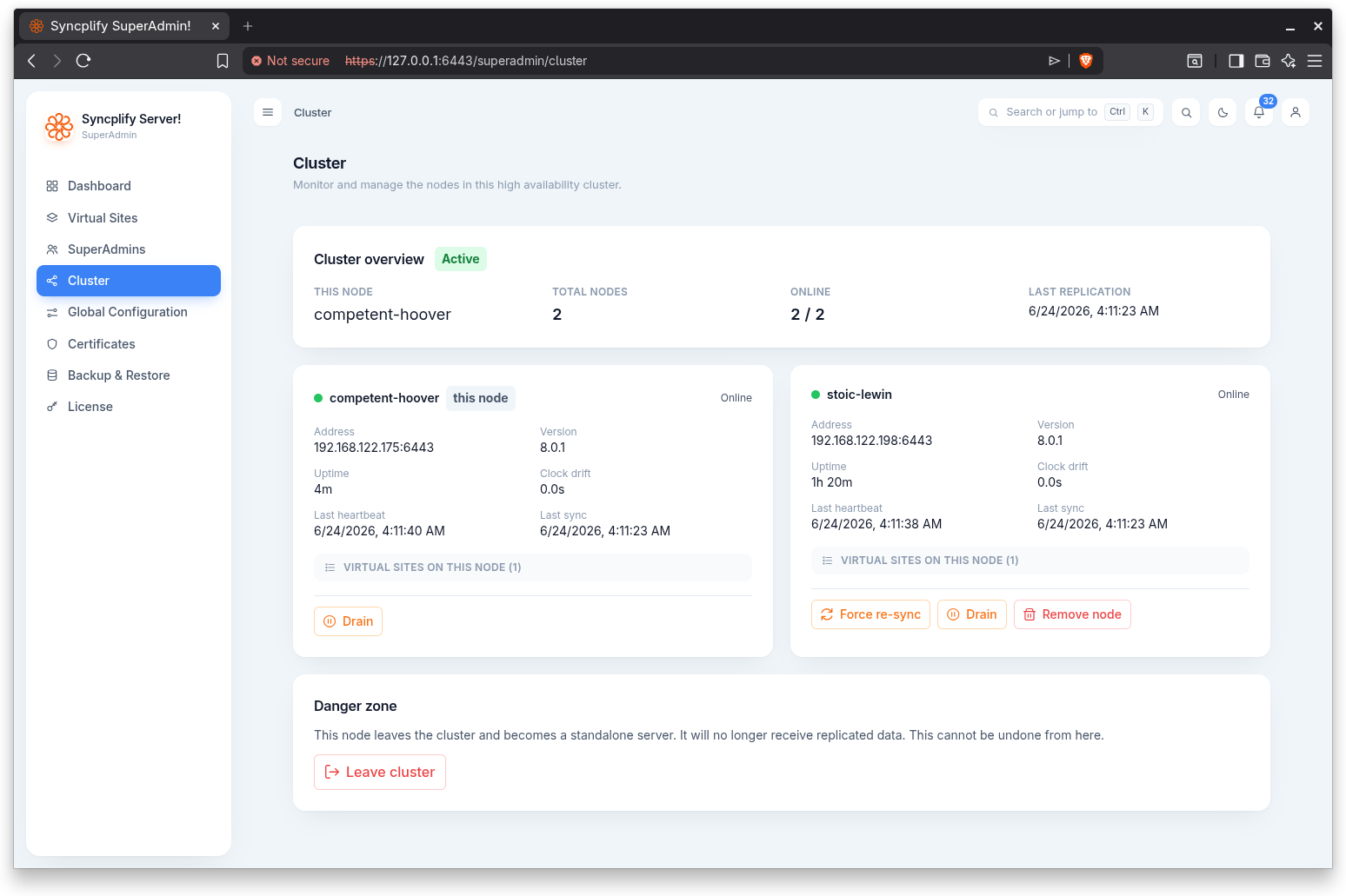
Per node cards
Each node is shown as a card with a status indicator and the node ID (your own node is tagged), plus address, version, uptime, clock drift, last heartbeat, and last sync. A draining or partially draining node is tagged accordingly.
Each card can expand to list the virtual sites running on that node, with their live session counts and current status.
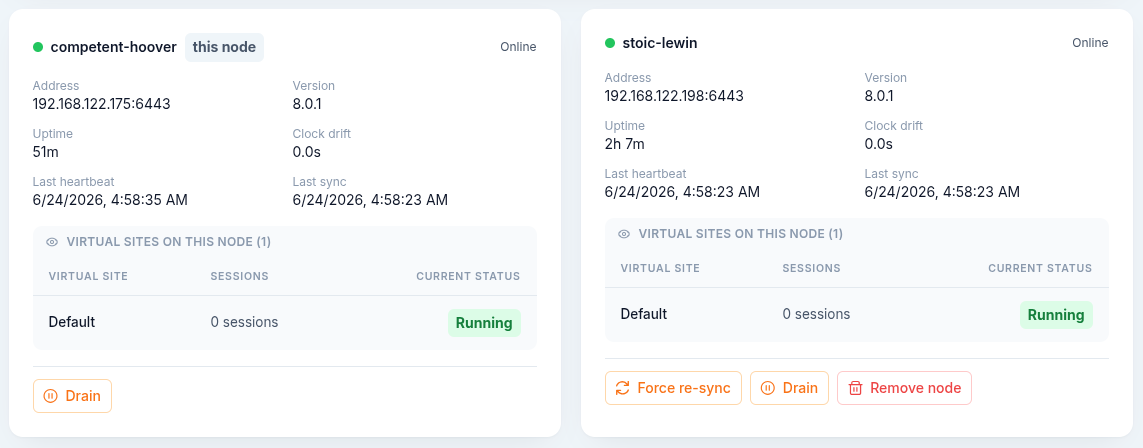
Node actions
Depending on the node and its state, a card offers:
- Force re-sync: forces a full re-sync of all data from a peer node to this node. Use it only when replication has fallen out of sync. This is a disruptive action and asks for confirmation.
- Drain: drains the node so its virtual sites stop accepting new connections while existing sessions finish. A confirmation dialog lists the affected virtual sites and their live session counts.
- Undrain: resumes accepting new connections on the node. This runs immediately.
- Remove node: removes the node from the cluster. This is a disruptive action and asks for confirmation.
Danger zone
A Leave cluster action makes this node leave the cluster and become a standalone server. It will no longer receive replicated data, and this cannot be undone from here. It asks for confirmation.